CeZ
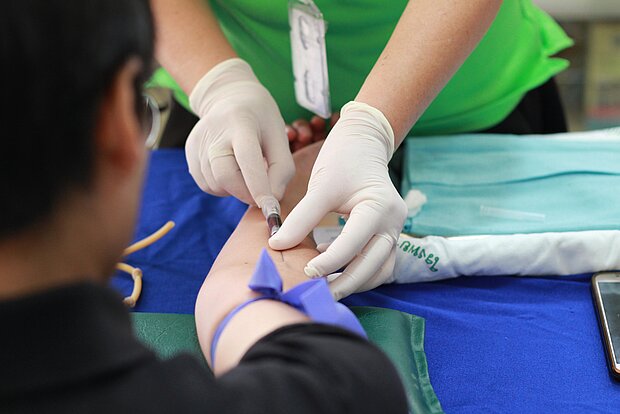
e-Blood
Das Projekt umfasste die Migration und Normalisierung medizinischer Daten, die in 24 Einrichtungen des Regionalen Blutspende- und Hämatologiezentrums gesammelt wurden, in das e-Blood-System.
Branche: Gesundheitswesen
Technologie: Vertragsgestaltung basierend auf XSD files, Datenmigration aus XML-Dateien, CI auf Basis von Jenkins, Angular, Java 8, Keycloak, Datenbanktransformationen von DB2 zu PostgreSQL, ETL auf Basis von SQL-Skripten
Kunde: e-Health Center (CeZ) und der nationale Gesundheitsfond (NFZ)
Der Arbeitsbereich des eHealth-Zentrums (CeZ) ist die Entwicklung von Informationssystemen im Gesundheitswesen. Der Nationale Gesundheitsfonds (NHF) ist das universelle Gesundheitssystem des Staates.
Migration und Datenverarbeitung in Zahlen:
- 5.6 Mio. Persönliche Dateien
- 5.2 Mio. Spender
- 8 Mio. Adressen
- 14 Mio. Spenden
Sie haben Fragen oder wünschen sich eine persönliche Beratung?
Wir sind gerne für Sie da. Nehmen Sie über unser Kontaktformular oder telefonisch Kontakt zu uns auf.